|
|
Research
Acoustic feature extraction
MFCC
MFCC (Mel frequecy cepstral coefficient) are the most common features extracted from the acoustic signal for automatic speech recognition.
The acoustic signal of the German word "Bahnhof" (Spectrogramm)

The acoustic signal for each of the six phonemes of the word "Bahnhof"(/ba:nho:f/)
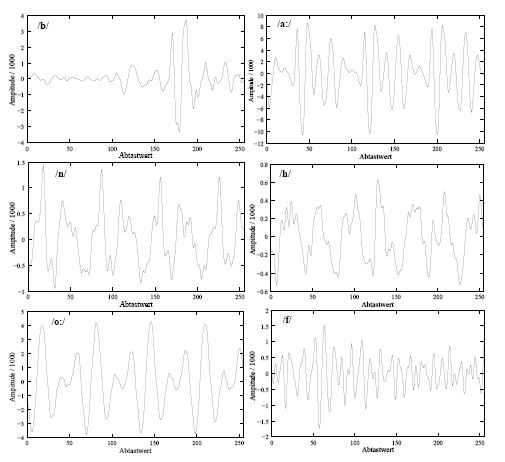
Converting phonemes into frequency domain: The spectrum (logarithmized) for each of the six phonemes of the word "Bahnhof"(/ba:nho:f/)
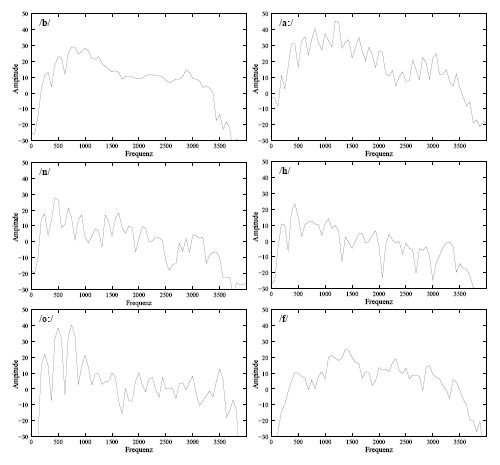
Sampling on the Mel-scale: The Mel-spectrum for each of the six phonemes of the word "Bahnhof"(/ba:nho:f/)
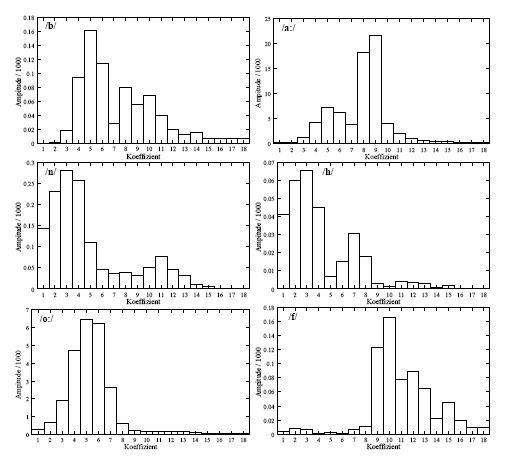
The logarithmized Mel spectrum (+ energy) for each of the six phonemes of the word "Bahnhof"(/ba:nho:f/)
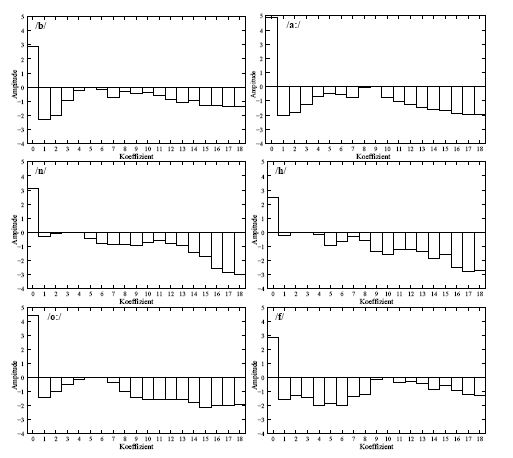
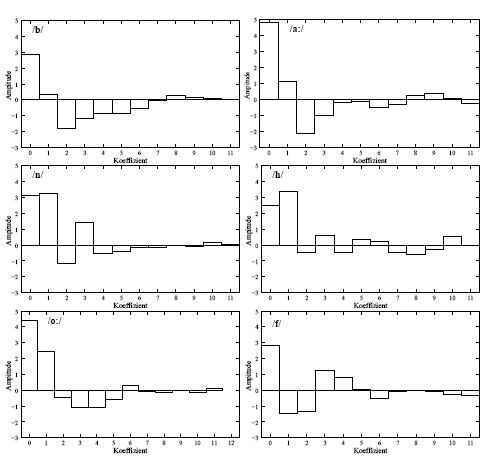
Decorrelation of spectral information: The cepstrum (inverse Fourier transformed spectrum) for each of the six phonemes of the word "Bahnhof"(/ba:nho:f/)
Further information can be found in:
Hacker, Christian
Optimierung der Merkmalberechnung für die automatische Spracherkennung,
Studienarbeit,
Lehrstuhl für Mustererkennung,
Friedrich-Alexander-Universität Erlangen, 2001
[download]
PLP features
see:
Hönig, Florian; Stemmer, Georg; Hacker,
Christian; Brugnara, Fabio
Revising Perceptual Linear
Prediction (PLP) In: ISCA (Eds.) Proceedings of the 9th
European Conference on Speech Communication and
Technology (9th European Conference on Speech Communication and
Technology - Interspeech 2005 Lisbon 4-8.9.2005) Bonn : ISCA 2005, pp.
2997-3000 - ISBN 1018-4074
Delta features
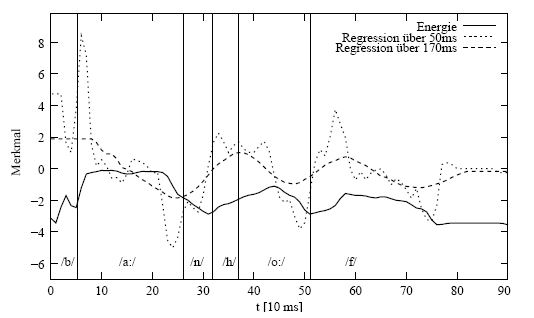
To encode dynamic information of the time spectrum, usually 1st and 2nd order derivatives of the MFCC features are used. The figure shows the investigated problem, to improve recognition rates when computing the 1st order derivatives over different time windows- The solid line shows the energy contour of the German word "Bahnhof", the other lines differently computed derivatives:
Further information can be found in:
Hacker, Christian
Optimierung der Merkmalberechnung für die automatische Spracherkennung,
Studienarbeit,
Lehrstuhl für Mustererkennung,
Friedrich-Alexander-Universität Erlangen, 2001
[download]
Stemmer, Georg; Hacker, Christian; Nöth, Elmar; Niemann, Heinrich
Multiple Time Resolutions for Derivatives of Mel-Frequency Cepstral
Coefficients
In: ASRU (Eds.) Proceedings of the Automatic Speech Recognition and
Understanding
Workshop (ASRU'01) 2001
TRAP features
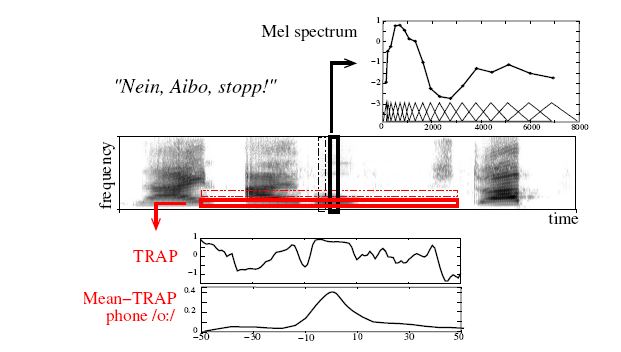
TRAP features (TempoRAl Patterns) analyze the context information within a spectral band.
Further information can be found in:
Hacker, Christian; Steidl, Stefan, Elmar Nöth, Anton Batiner:
Spectral and TRAP-Based Characterization of Children's Speech
, technical report,
Lehrstuhl für Mustererkennung,
Friedrich-Alexander-Universität Erlangen, 2004
[download]
Maier, Andreas; Hacker, Christian; Steidl, Stefan; Nöth, Elmar
Helfen "Fallen" bei verrauschten Daten? -
Spracherkennung mit TRAPs In: Fastl, Hugo; Fruhmann, Markus
(Eds.) Fortschritte der Akustik: Plenarvorträge und
Fachbeiträge der 31.
Deutschen Jahrestagung für Akustik DAGA 2005, München
(31. Deutsche
Jahrestagung für Akustik, DAGA '05 München 14. bis
17. März 2005) Vol.
1 Berlin : Deutsche Gesellschaft für Akustik e.V. 2005, pp.
315-316 -
ISBN 3-9808659-1-6
Automatic speech recognition
The standard apporach for automatic speech recognition is based on HMM (Hidden Markov Models).
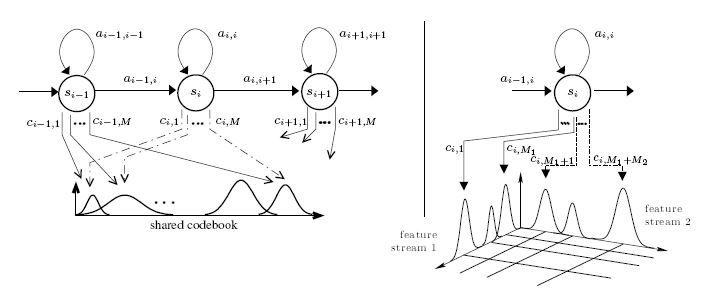
The mapping between HMM states and the acoustic signals (the acoustic features as described above) is done via codebooks, i.e.
a distribution showing the probability of observing feature vector c given state s.
The following image shows the investigated problem of using differnt codebooks for different feature types, e.g. assuming MFCC features and delta features to be statisticaly independent. The problem is investigated using semi-continuous HMM, where one single codebook is shared among all HMM states, but where the densities of the codebook a weighted HMM state dependently.
Further information can be found in:
Hacker, Christian
Semikontinuierliche Hidden-Markov-Modelle mit mehreren Kodebüchern,
Diplomarbeit,
Lehrstuhl für Mustererkennung,
Friedrich-Alexander-Universität Erlangen, 2002
[download]
Hacker, Christian; Stemmer, Georg; Steidl, Stefan; Nöth, Elmar; Niemann, Heinrich
Various Information Sources for HMM with Weighted
Multiple Codebooks In: Wendemuth, A. (Eds.) Proceedings of
the Speech Processing Workshop, Magdeburg, Germany,
September 09 (Speech Processing Workshop Magdeburg, Germany September
09, 2003) - : - 2003, pp. 9-16
Stemmer, Georg; Zeissler, Viktor; Hacker, Christian; Nöth, Elmar; Niemann, Heinrich
Context-Dependent Output Densities for Hidden
Markov Models in Speech Recognition In: IDIAP
(Dalle Molle Institute for Perceptual Artificial Intelligence,
Martigny); University of Geneva (ISSCO/ETI); EPFL (Swiss Federal
Institute of Technology, Lausanne); ETHZ (Swiss Federal Institute of
Technology, Zürich) (Eds.)
Proc. European Conf. on Speech
Communication and Technology (European Conf. on Speech Communication
and Technology Geneva, Switzerland September 2003) Vol. 2 2003, pp.
969-972
|
