|
|
Research
Assessment of non-native speakers
Is it possible that a computer judges whether the pronunciation of words and sentences in a foreign language is good enough?
Can a computer help us while learning a new language, can it give us useful hints, can it even listen to us and assess us during any conversation
in real life? Can a computer replace teachers to train children?
A machine is very good in comparing data to a reference. We can also
build statistical models to have a more fuzzy reference to cover variability and different ways of pronouncing the same phrases correctly.
Nowadays it is even possible to train very reliant models using deep learning and big data.
However, not for all pairs of languages we have currently enough data, also not for all speaker groups, e.g. children of a certain age.
We can improve our algorithms by designing what to be measured and deciding which of those measurements are most important. And finally
we need to think about what needs to be assessed when observing ratings with variability, i.e. disagreement among human raters about which pronunciation
is really good. Some answers to this are the extraction of accoustic and prosodic features and the usage of speech recognizers or language specific knowledge.
A trained combination of this information during feature selection provides a stable input to a classifier resulting in a fuzzy classification score.
These scores need then to be compared to the also fuzzy rating created from the evaluation of human teachers.
My PhD Thesis
Title: Automatic Assessment of Children
Speech to Support Language Learning.
German title: Automatische
Bewertung der Sprache von Kindern als Hilfe
beim Fremdsprachenlernen (Logos
Verlag, Berlin)
Download thesis:
thesis_hacker.pdf
Download
presentation: presentation_hacker.pdf
Download
presentation incl. audio: presentation_and_audio_hacker.zip
Abstract
Focus of this work are pattern recognition related aspects of computer assisted
pronunciation training (CAPT) for second language learning.
An overview of commercial systems shows that pronunciation training is being
addressed by the growing Field of computer assisted language learning only to a small
extend, although in the state-of-the-art section a number of such approaches for automatic
assessment can already be presented. In the present thesis different approaches are
extended and combined. In particular a large set of nearly 200 pronunciation and prosodic
features is developed. By this approach pronunciation scoring is considered as classification
task in high-dimensional feature space.
Automatic speech recognition is the basis of most pronunciation scoring algorithms. In
this thesis a system is presented, which supports second language learning in school, i.e.
the target users are children. For this reason a state-of-the-art speech recognition engine is
adapted to children speech, since young speakers are only hardly recognised by automatic
systems. Phonetically motivated rules for typical mispronunciation errors are integrated
into the system to make it suitable for pronunciation scoring.
Evaluating an algorithm for pronunciation assessment is more difficult than simply
counting the correctly recognised mistakes, since there exists no objective ground truth.
This can be shown by evaluating the annotations of 14 teachers. However, with different
measures it can be verified that the accuracy of the system (in comparison with teachers)
thoroughly reaches the agreement among teachers. The evaluation is conducted with native
German speakers learning English.
Investigated problem
- How good is the pronunciation of young German learners of Englisch?
- How can the goodness of pronunciation be measured?
System:
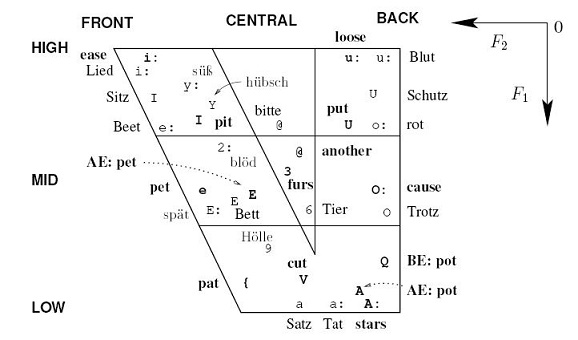
The image shows formants of German and English vowels. Many vowels exist only in one language.
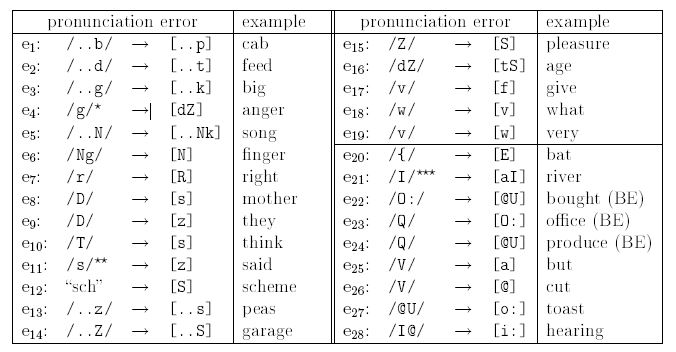
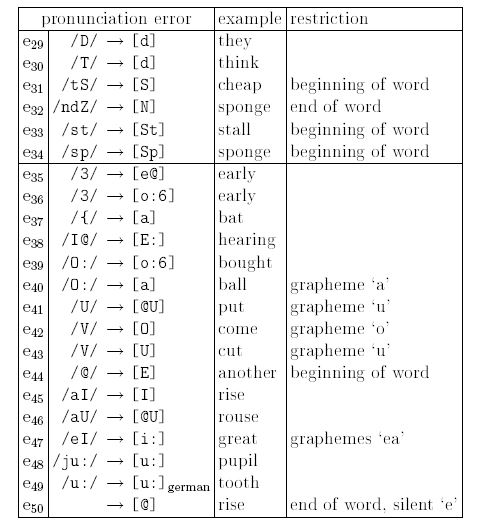
The tables show typical mispronunciations of German learners of English (top: from literature; buttom: observed in the thesis). Each error rule maps the correct pronunciation onto wrong phonemes used by learners of English. These rules are used to build acoustic models for wrongly pronounced words (mispronunciation models) to detect false pronunciations using automatic speech recognition.
Classification
- A large amount of features is used for classification
- Features describing the prosody on word level (prosodic features)
- Features describing automatic speech recognition quality on word level (pronunciation features)
- Features comparing speech recognition and intended text (pronunciation features)
Examples for prosodic features (red) and pronunciation features (blue):
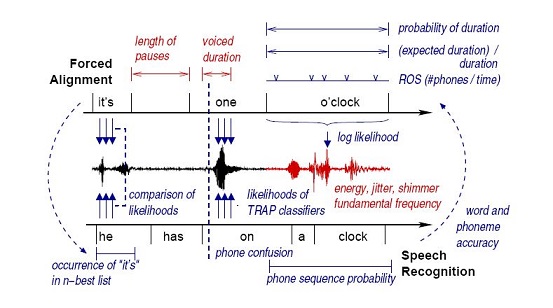
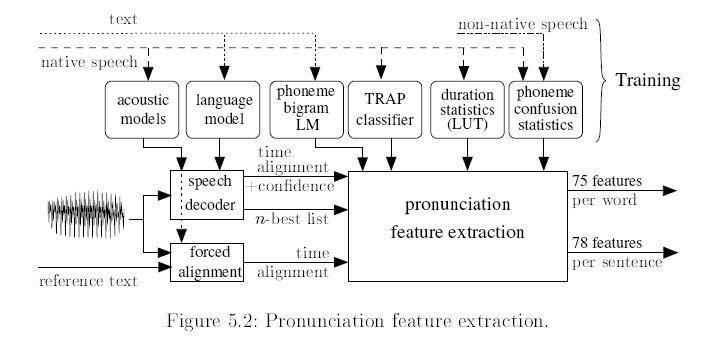
Computation of pronunciation features:
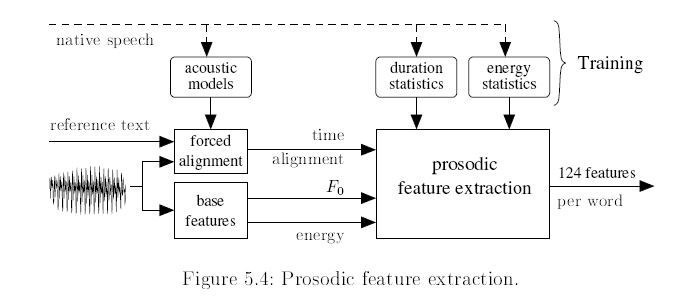
Computation of prosodic features:
Features selection and classification is done with AdaBoost.
Additionally speech recognition with a large amount of mispronunciation models is performed.
Both evaluation algorithms are combined e.g. on word level. Meta-features are calculated from the sub-systems before fusion is performed in low dimensional feature space:
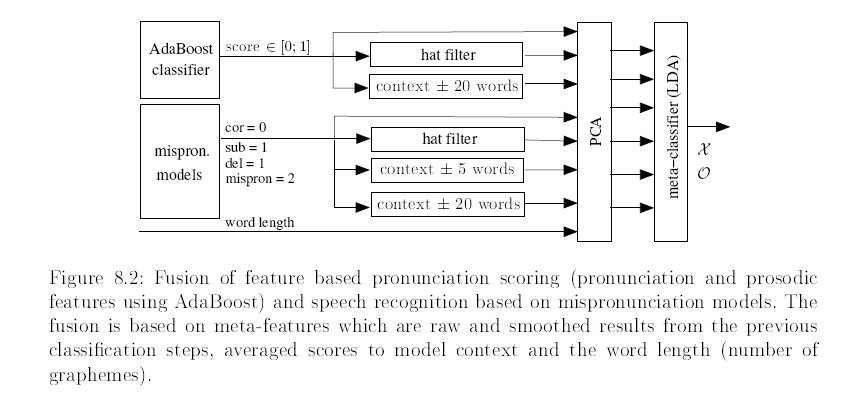
Experimental Results
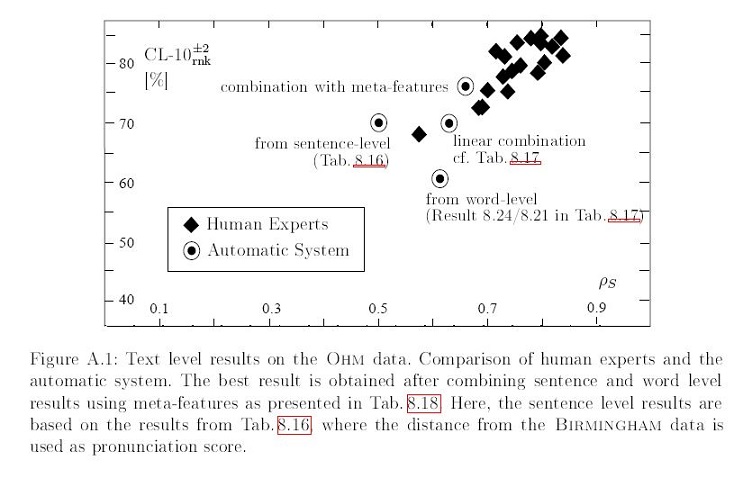
Comparing experts (teachers) and the automatic system on text level. The investigated database has been annotated by 14 teachers. It can be seen that the distance between the automatic system and the teachers is similar as the distance among some of the teachers.
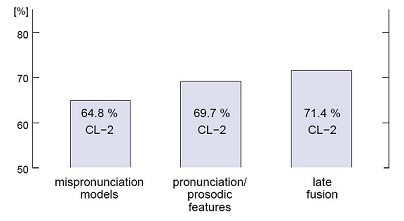
Comparing experts (teachers) and the automatic system on word level:
Own Publications
all publications
Hacker, Christian
Automatic
Assessment of Children Speech to Support Language Learning
Berlin: Logos Verlag, 2009
Cincarek, Tobias; Gruhn, Rainer; Hacker, Christian; Nöth, Elmar; Nakamura, Satoshi
Automatic Pronunciation Scoring of Words and
Sentences Independent from the Non-Native's First Language
In: Computer Speech & Language 23 (2009) No. 1 pp. 65-88
Hacker, Christian; Maier, Andreas; Heßler, Andre; Guthunz, Ute; Nöth, Elmar
Caller: Computer Assisted Language Learning from
Erlangen - Pronunciation Training and More In: Auer, Michael
E. (Eds.)
Proc. Int. Conf. Interactive Computer Aided Learning (ICL)
(International Conference ICL: ePortfolio and Quality in e-learning
Villach/Austria 26.-29.9.2007) Kassel : kassel university press 2007,
pp. 6 pages, no pagination - ISBN 978-3-89958-279-6
Hacker, Christian; Cincarek, Tobias; Maier, Andreas; Heßler, Andre; Nöth, Elmar
Boosting of
Prosodic and Pronunciation Features to Detect Mispronunciations of
Non-Native Children In: IEEE Signal Processing Society (Eds.)
ICASSP, 2007 IEEE International Conference on Acoustics, Speech, and
Signal Processing, Proceedings (ICASSP - International Conference on
Acoustics, Speech, and Signal Processing Honolulu, Hawaii, USA
15-20.4.2007) Vol. 4 Bryan, TX : Conference Managament Services, Inc.
2007, pp. 197-200 - ISBN 1-4244-0728-1
[download poster]
Hacker, Christian; Batliner, Anton; Steidl, Stefan; Nöth, Elmar; Niemann, Heinrich; Cincarek,
Tobias
Assessment of Non-Native Children's Pronunciation:
Human Marking and Automatic Scoring
In: Kokkinakis, G.; Fakotakis, N.; Dermatas, E.; Potapova, R. (Eds.)
SPEECOM 2005 Proceedings, 10th International Conference on SPEECH and
COMPUTER (10th International Conference on Speech and Computer (SPECOM
2005) Patras, Greece 17.10.2005 - 19.10.2005) Vol. 1 Moscow, Patras :
Moskow State Linguistics University 2005, pp. 123 - 126 - ISBN
5-7452-0110-x
Hacker, Christian; Cincarek, Tobias; Gruhn, Rainer; Steidl,
Stefan; Nöth, Elmar; Niemann, Heinrich
Pronunciation
Feature Extraction
In: Kropatsch, Walter; Sablatnig, Robert; Hanbury, Allan (Eds.) Pattern
Recognition, 27th DAGM Symposium (27th Annual meeting of the
German Association for Pattern Recognition (DAGM 2005) Wien 31.08.2005
- 02.09.2005) Berlin : Springer 2005, pp. 141-148 - ISBN 3-540-28703-5
|
